Cleaning Medical Data
with R
Instructors
Crystal Lewis

Shannon Pileggi

Peter Higgins

Scope

Taming the Data Beast, by Allison Horst
Taming the Data Beast, from Allison Horst’s Data Science Illustrations
R for Data Science: Ch 18 Pipes

Data Horror Stories
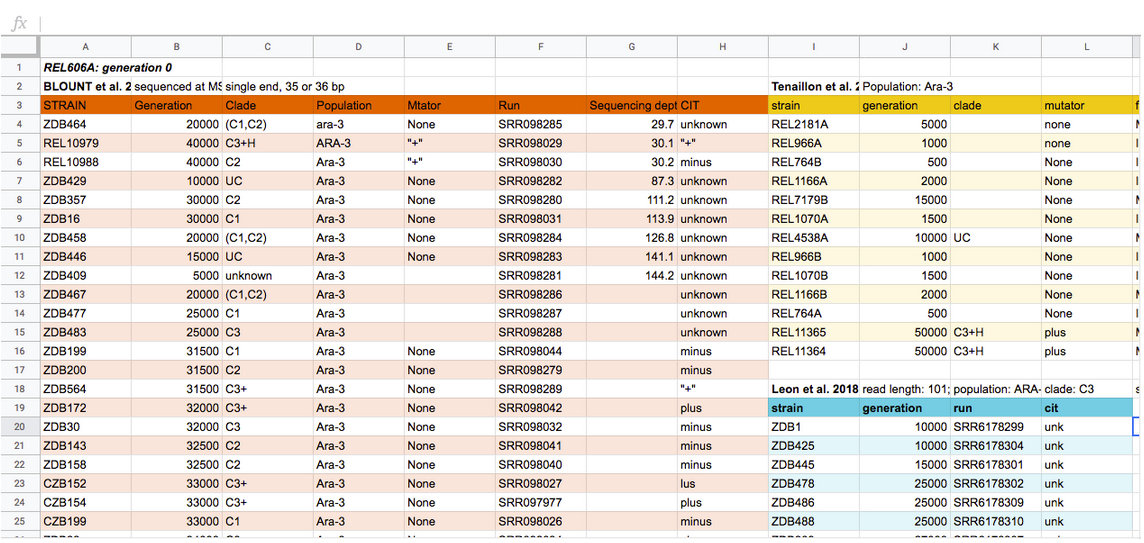
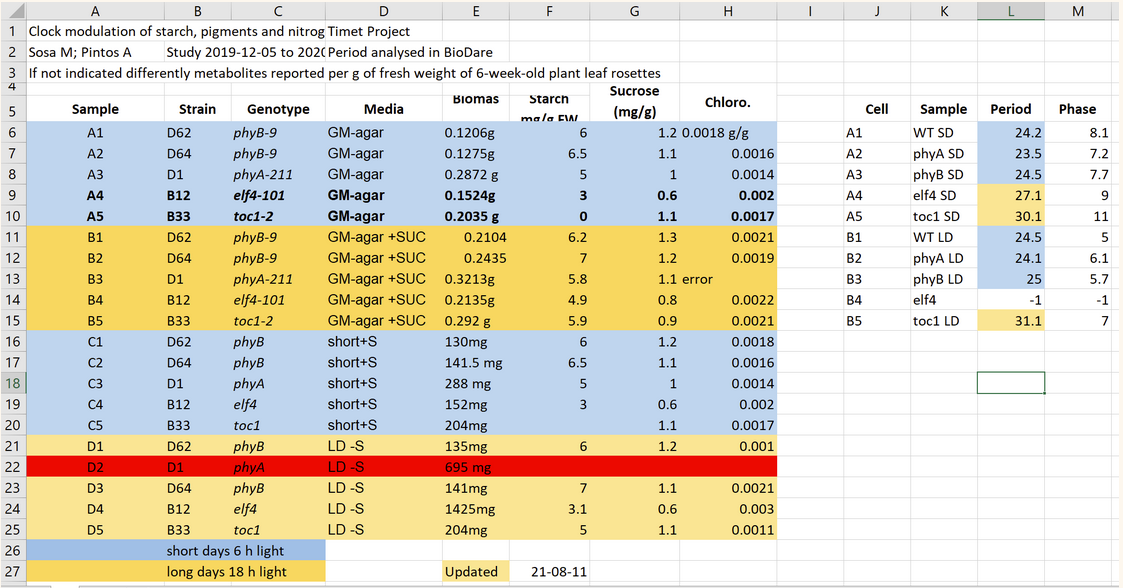
Data Horror Stories

Data Organizing Principles
- Data Structure
- Variable Values
- Variable Types
- Missing Data
Data Structure
- Data should make a rectangle of rows and columns
- You should have the expected number of rows (cases in your data)
- You should have the expected number of columns (variables in your data)
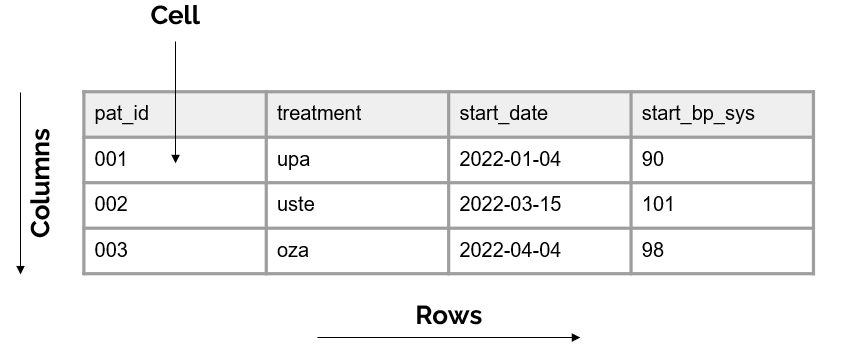
Exercise
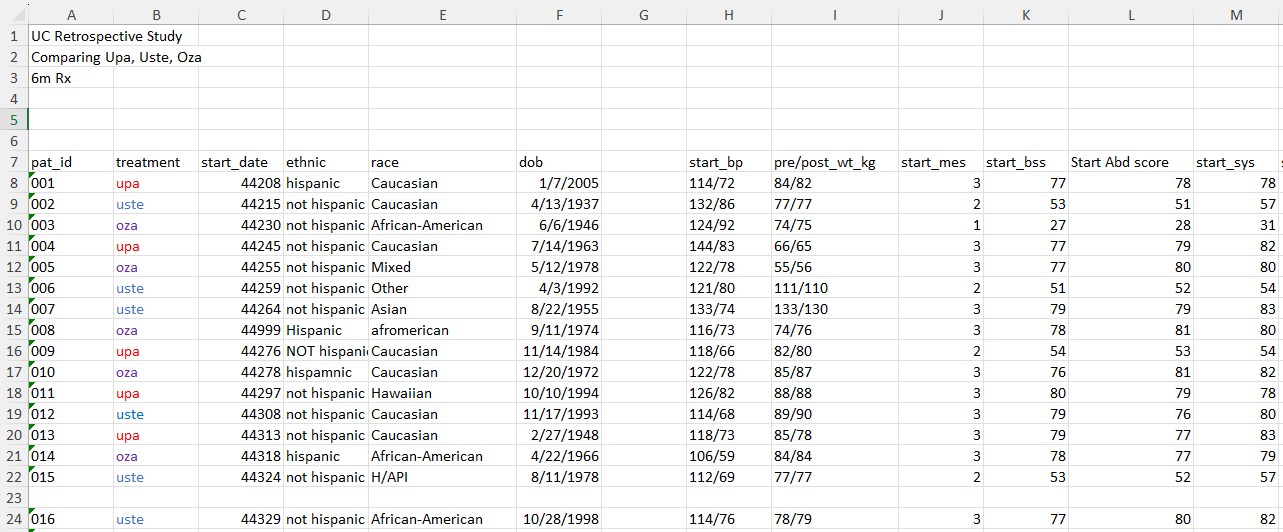
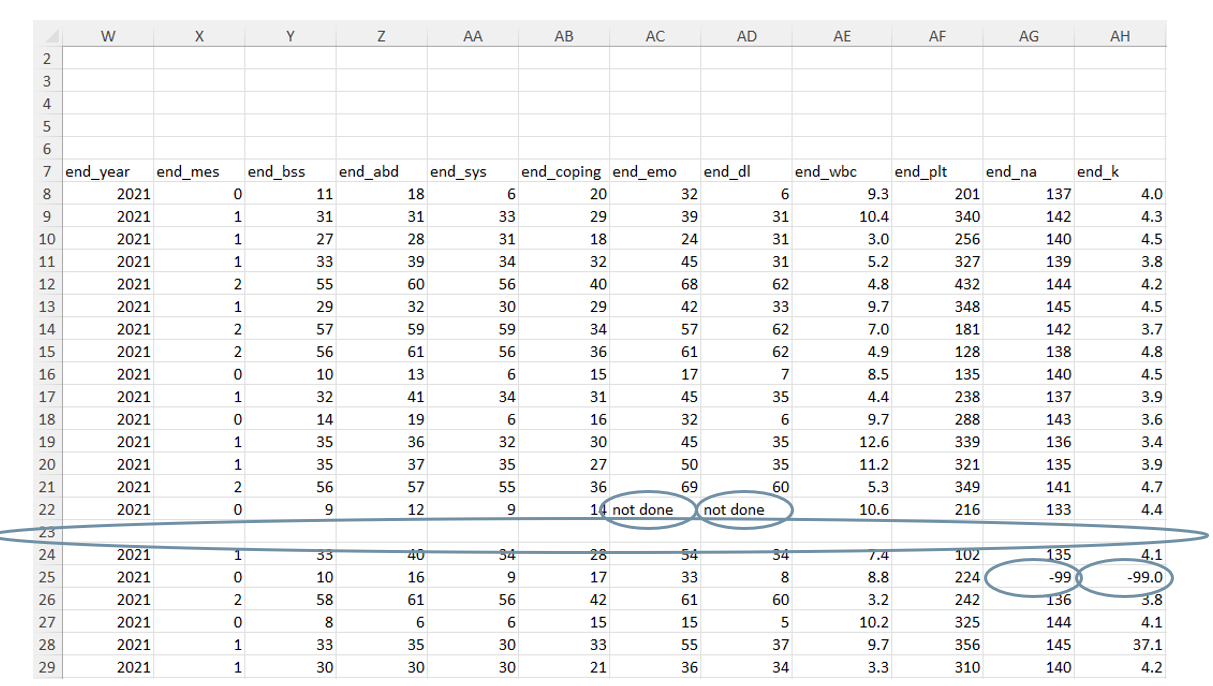
What data structure issues do you notice in our sample data?
01:00
Data Structure
- Variable names are not the first row of the data
- Our data does not make a rectangle - Empty column, empty rows
- Variable names do not adhere to best practices

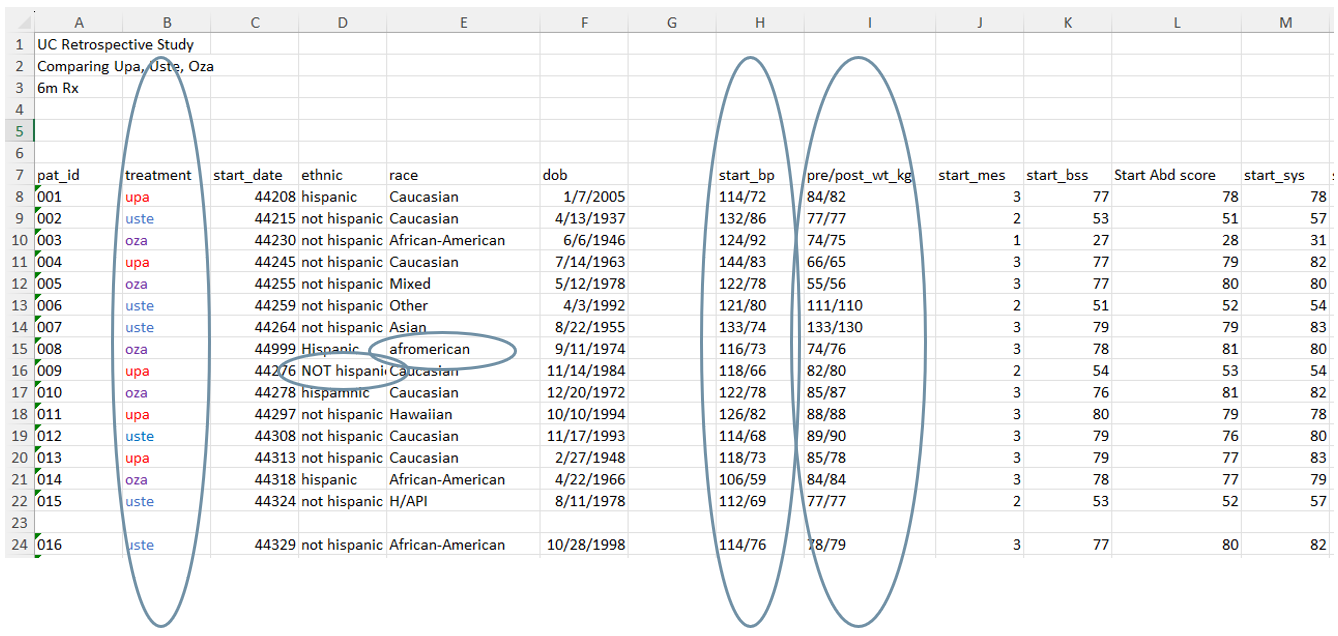
Exercise
What variable value issues do you notice in our sample data?
01:00
Variable Values
- Color coding used to indicate information
- Two things measured in one column
- Categorical values captured inconsistently
Exercise
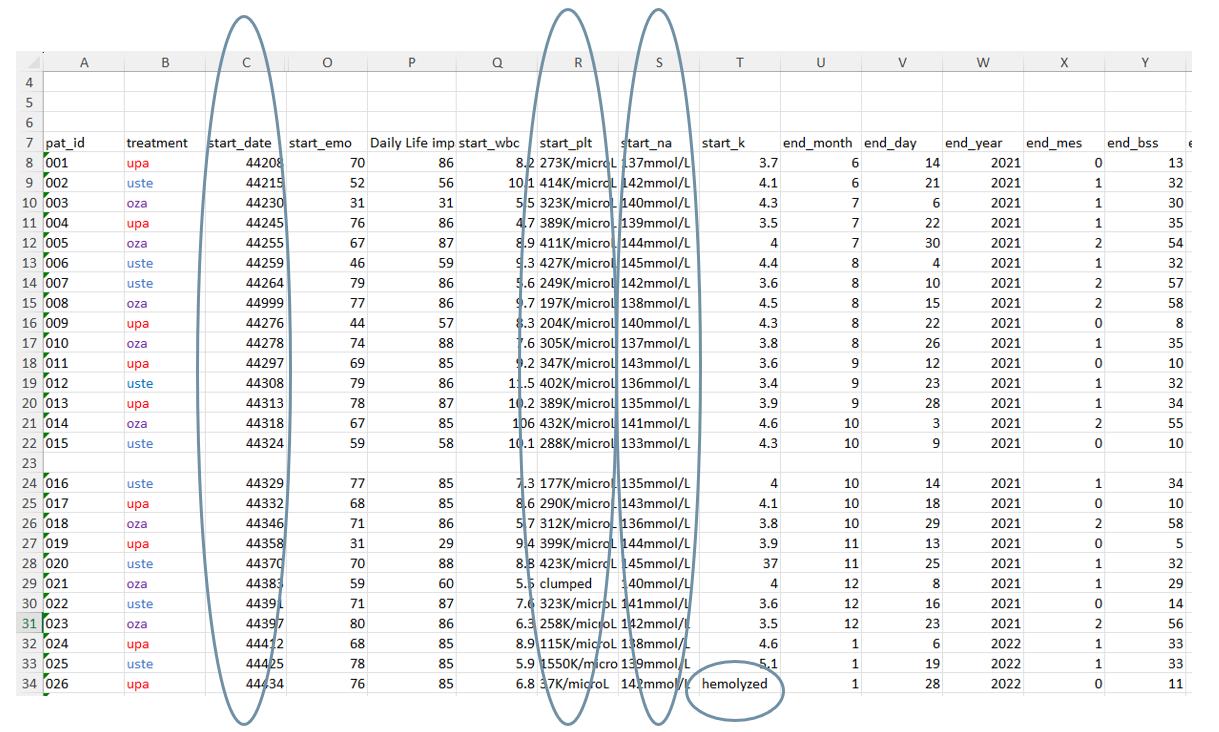
What variable type issues do you notice in our sample data?

01:00
Variable Types
- Dates stored as numbers
- Text stored in numeric variables
Exercise
What missing data issues do you notice in our sample data?
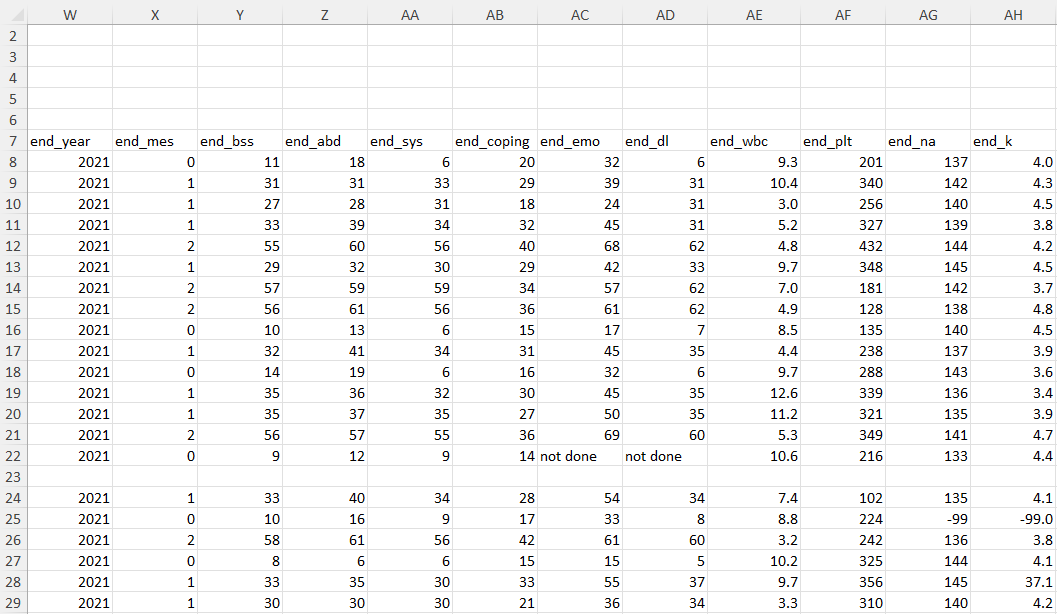
01:00
Missing Data
- Unexpected missing data
- Inconsistent missing values used
- Missing values do not match variable type
pointblank report
library(pointblank)
# Import my data
df_raw <- readxl::read_excel("data/mydata.csv")
# Check my assumptions
create_agent(df_raw) |>
rows_distinct(columns = vars(pat_id)) |>
col_vals_not_null(columns = vars(pat_id)) |>
col_is_date(columns = vars(start_date)) |>
col_is_numeric(columns = vars(start_mes)) |>
col_vals_in_set(columns = vars(treatment), set = c("upa", "uste", "oza")) |>
col_vals_in_set(columns = vars(ethnic), set = c("hispanic", "not hispanic")) |>
col_vals_between(columns = vars(start_mes), left = 0, right = 3, na_pass = FALSE) |>
interrogate()![]()
codebookr codebook
Exercise
Take 5 minutes to review the data dictionary and our data.
- Log in to Posit Cloud and navigate to our project
- Open the data folder and open the file “messy_uc.xlsx”
When you finish, give us a 👍
If you are having trouble, give us a ✋
05:00
Import our file
| pat_id | treatment | start_date | ethnic | race | dob | ...7 | start_bp | pre/post_wt_kg | start_mes |
|---|---|---|---|---|---|---|---|---|---|
| 001 | upa | 44208 | hispanic | Caucasian | 2005-01-07 | NA | 114/72 | 84/82 | 3 |
| 002 | uste | 44215 | not hispanic | Caucasian | 1937-04-13 | NA | 132/86 | 77/77 | 2 |
| 003 | oza | 44230 | not hispanic | African-American | 1946-06-06 | NA | 124/92 | 74/75 | 1 |
| 004 | upa | 44245 | not hispanic | Caucasian | 1963-07-14 | NA | 144/83 | 66/65 | 3 |
| 005 | oza | 44255 | not hispanic | Mixed | 1978-05-12 | NA | 122/78 | 55/56 | 3 |
| 006 | uste | 44259 | not hispanic | Other | 1992-04-03 | NA | 121/80 | 111/110 | 2 |
| 007 | uste | 44264 | not hispanic | Asian | 1955-08-22 | NA | 133/74 | 133/130 | 3 |
| 008 | oza | 44999 | Hispanic | afromerican | 1974-09-11 | NA | 116/73 | 74/76 | 3 |
| 009 | upa | 44276 | NOT hispanic | Caucasian | 1984-11-14 | NA | 118/66 | 82/80 | 2 |
| 010 | oza | 44278 | hispamnic | Caucasian | 1972-12-20 | NA | 122/78 | 85/87 | 3 |
Review the data
EDA is not a formal process with a strict set of rules. More than anything, EDA is a state of mind. During the initial phases of EDA you should feel free to investigate every idea that occurs to you. - R for Data Science

summarytools::dfSummary()
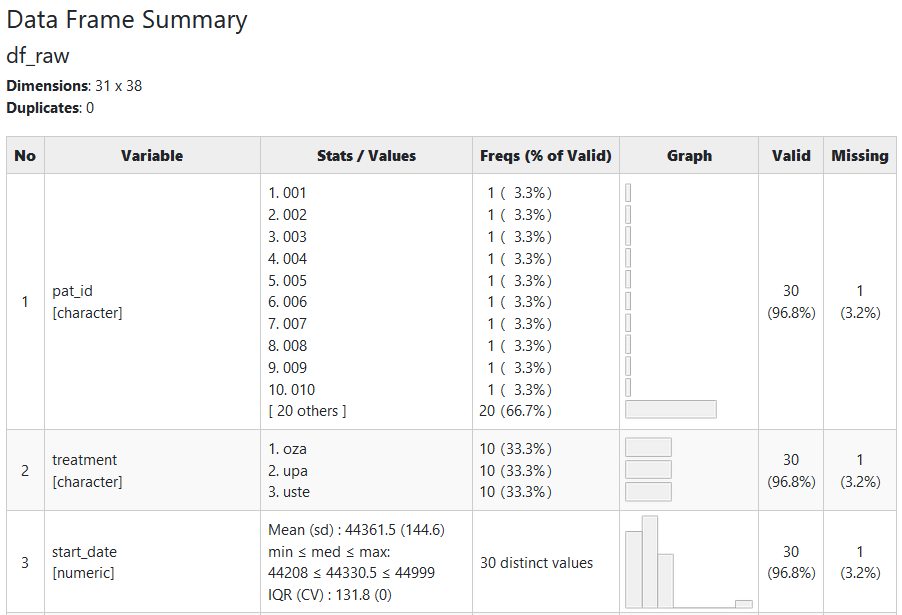
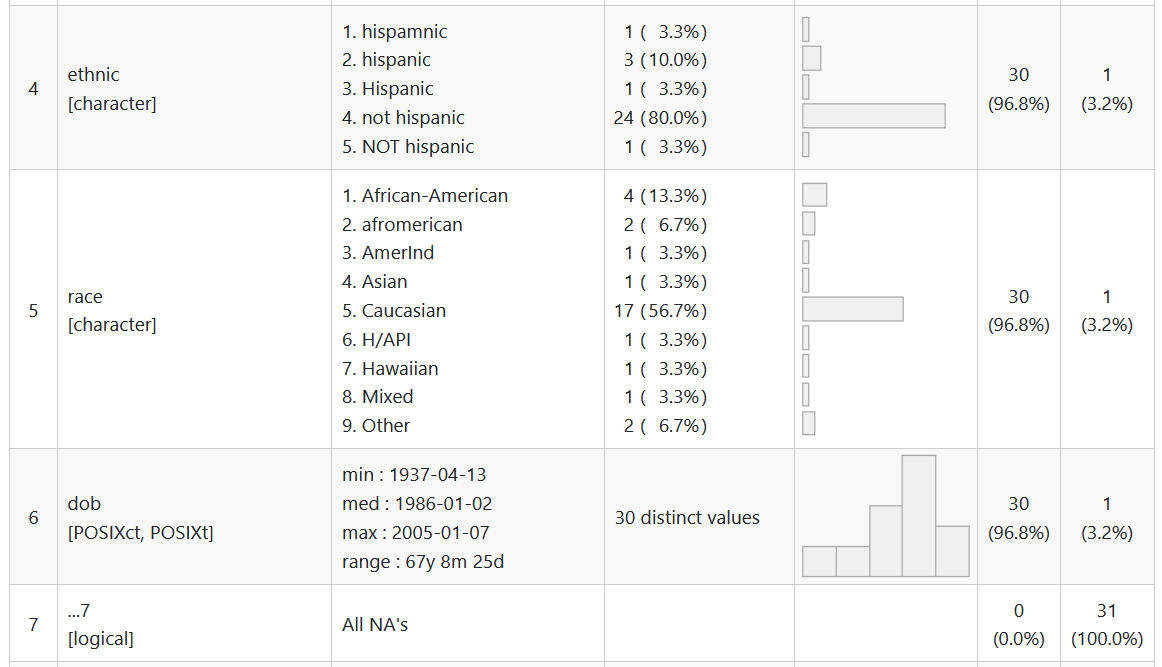
skimr::skim()
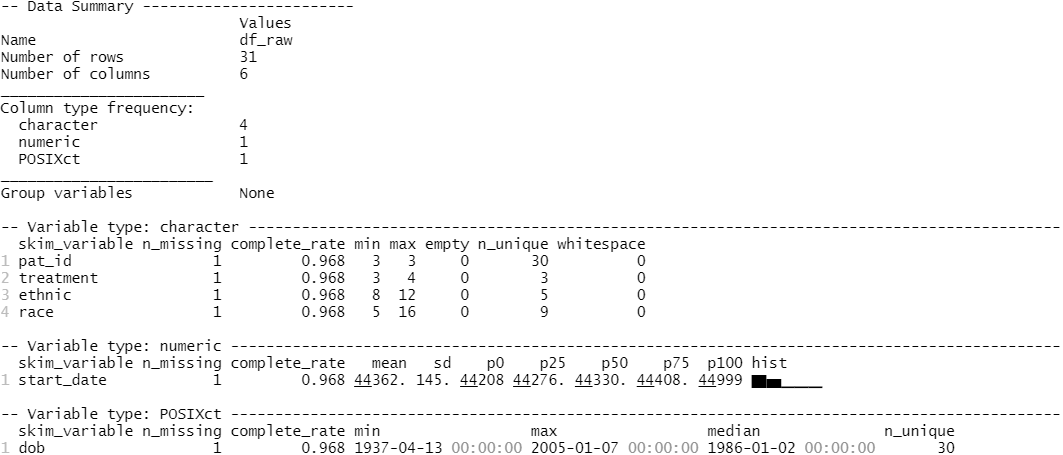
Variable names
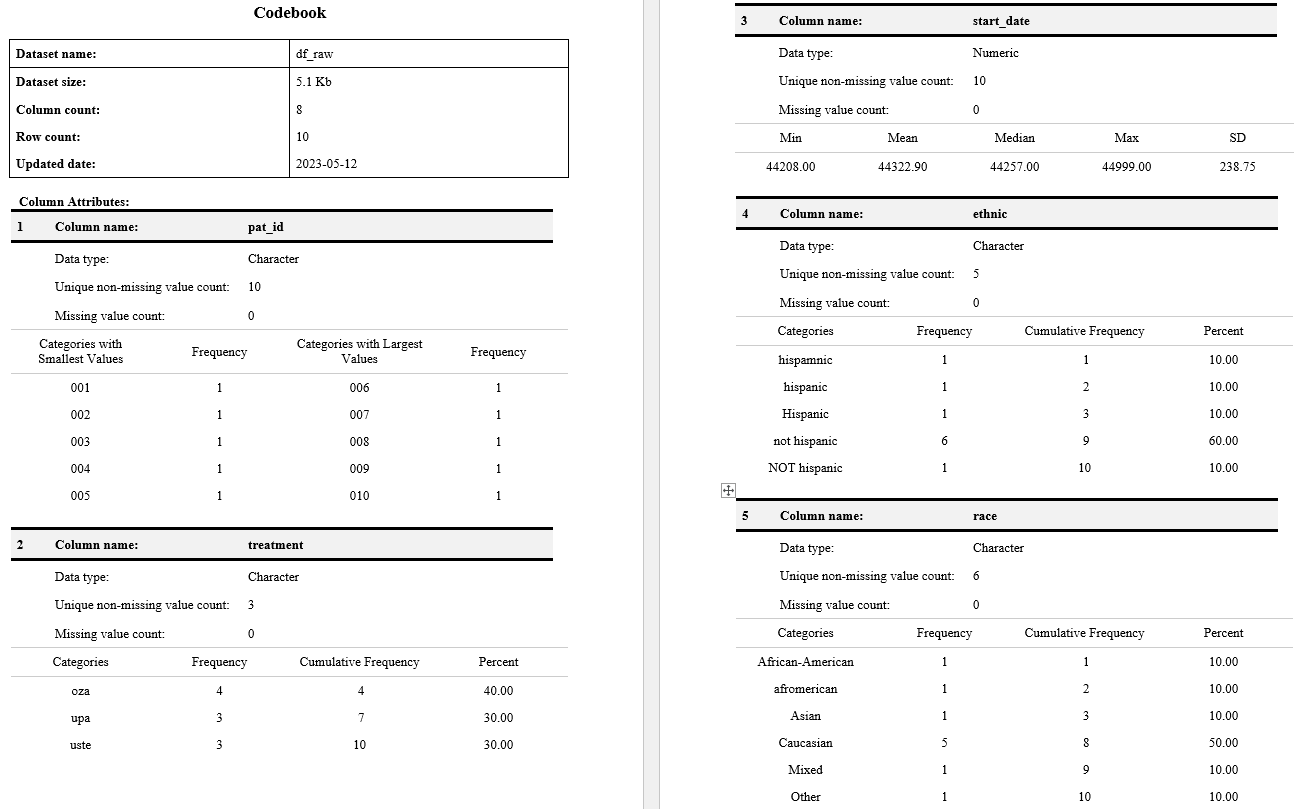
Original variable names in excel:

Variable names import as shown, with modifications from readxl::read_excel() to ensure uniqueness:

Variable names, cleaner
Variable names as imported:

Replace values with missing
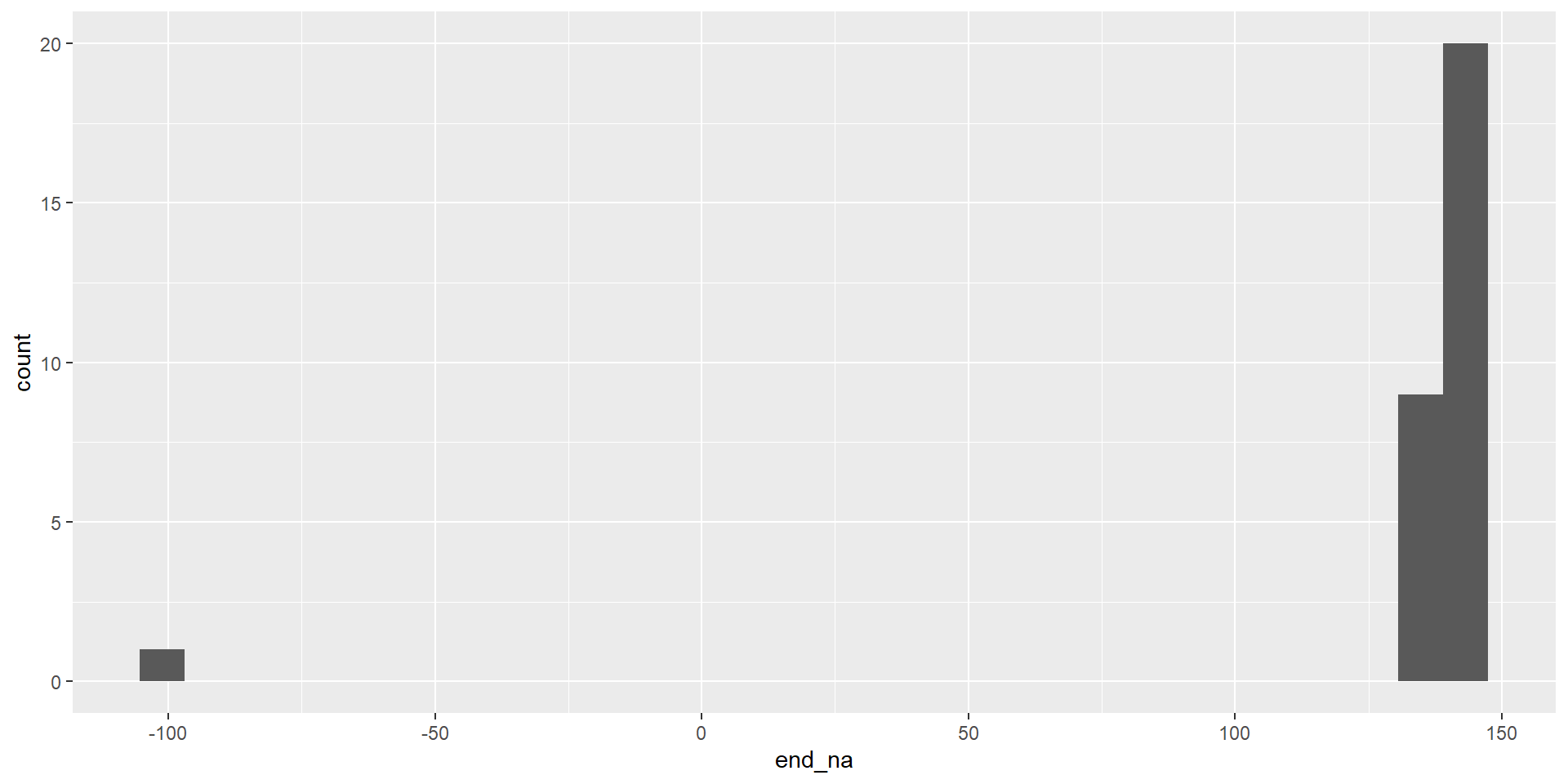
df_clean <- df_raw |>
janitor::clean_names() |>
janitor::remove_empty(which = c("rows", "cols")) |>
mutate(
ethnic_clean = case_when(
ethnic %in% c("hispanic", "Hispanic", "hispamnic") ~ "hispanic",
ethnic %in% c("NOT hispanic", "not hispanic") ~ "not hispanic",
),
end_na_clean = na_if(end_na, -99)
) 
Assigning labels
What does anything mean?
# first import data dictionary
df_dictionary <- read_excel(
path = here("data", "messy_uc.xlsx"),
sheet = "Data_Dictionary"
)
df_dictionary# A tibble: 33 × 5
Variable Details Units Range ...5
<chr> <chr> <chr> <chr> <chr>
1 pat_id Patient Identifier digi… 001-… <NA>
2 treatment Treatment for UC <NA> upad… <NA>
3 start_date Date of start of treatment digi… YYYY… <NA>
4 ethnic Ethnicity - hispanic or not hispanic <NA> hisp… <NA>
5 race Race - one of 7 choices <NA> cauc… <NA>
6 dob date of birth digi… YYYY… <NA>
7 start_bp blood pressure at start - systolic/diastolic mm Hg syst… <NA>
8 pre/post_wt_kg weight in kilograms at start/end kilo… 48-1… <NA>
9 start_mes Mayo endoscopic Score at start of treatment poin… 0-3 <NA>
10 start_bss Bowel symptom score at start poin… 0-100 QOL …
# ℹ 23 more rows# second create a named vector of variable names and variable labels
vec_variables <- df_dictionary |>
select(Variable, Details) |>
deframe()
vec_variables pat_id
"Patient Identifier"
treatment
"Treatment for UC"
start_date
"Date of start of treatment"
ethnic
"Ethnicity - hispanic or not hispanic"
race
"Race - one of 7 choices"
dob
"date of birth"
start_bp
"blood pressure at start - systolic/diastolic"
pre/post_wt_kg
"weight in kilograms at start/end"
start_mes
"Mayo endoscopic Score at start of treatment"
start_bss
"Bowel symptom score at start"
start_abd
"Abdominal symptom score at start"
start_sys
"Systemic symptom score at start"
start_coping
"Coping score at start"
start_emo
"Emotional symptom score at start"
start_dl
"Impact on Daily living score at start"
start_wbc
"White blood cell count in blood at start"
start_plt
"Platelet count in blood at start"
start_na
"Sodium level in serum at start"
start_k
"Potassium level in serum at start"
end_month
"Month of end visit"
end_day
"Day of end visit"
end_year
"Year of end visit"
end_mes
"Mayo endoscopic Score at end of treatment"
end_bss
"Bowel symptom score at end"
end_abd
"Abdominal symptom score at end"
end_sys
"Systemic symptom score at end"
end_coping
"Coping score at end"
end_emo
"Emotional symptom score at end"
end_dl
"Impact on Daily living score at end"
end_wbc
"White blood cell count in blood at end"
end_plt
"Platelet count in blood at end"
end_na
"Sodium level in serum at end"
end_k
"Potassium level in serum at end" # assign labels to the data set
df_clean <- df_raw |>
janitor::clean_names() |>
janitor::remove_empty(which = c("rows", "cols")) |>
mutate(
ethnic_clean = case_when(
ethnic %in% c("hispanic", "Hispanic", "hispamnic") ~ "hispanic",
ethnic %in% c("NOT hispanic", "not hispanic") ~ "not hispanic",
) |> fct_infreq(),
end_na_clean = na_if(end_na, -99),
end_emo_clean = na_if(end_emo, "not done") |> as.numeric(),
start_na_clean = parse_number(start_na),
treatment = fct_relevel(treatment, "upa", "uste", "oza")
) |>
separate_wider_delim(start_bp, delim ="/", names = c("bp_systolic", "bp_diastolic"), cols_remove = FALSE) |>
mutate(across(c(bp_systolic, bp_diastolic), as.numeric)) |>
# assign labels to all variables from the codebook
labelled::set_variable_labels(!!!vec_variables, .strict = FALSE) |>
# assign labels to new derived variables that did not exist in the code book
labelled::set_variable_labels(
ethnic_clean = "Ethnicity",
start_na_clean = "Sodium level in serum at start",
end_na_clean = "Sodium level in serum at end",
end_emo_clean = "Emotional symptom score at end",
bp_systolic = "Systolic blood pressure",
bp_diastolic = "Diastolic blood pressure"
)
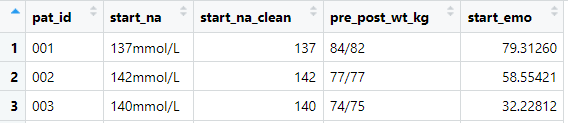
🤔 Why doesn’t pre_post_wt_kg have a label?
# view structure of data frame
df_clean |>
select(pat_id, start_na, start_na_clean, pre_post_wt_kg, start_emo) |>
str()tibble [30 × 5] (S3: tbl_df/tbl/data.frame)
$ pat_id : chr [1:30] "001" "002" "003" "004" ...
..- attr(*, "label")= chr "Patient Identifier"
$ start_na : chr [1:30] "137mmol/L" "142mmol/L" "140mmol/L" "139mmol/L" ...
..- attr(*, "label")= chr "Sodium level in serum at start"
$ start_na_clean: num [1:30] 137 142 140 139 144 145 142 138 140 137 ...
..- attr(*, "label")= chr "Sodium level in serum at start"
$ pre_post_wt_kg: chr [1:30] "84/82" "77/77" "74/75" "66/65" ...
$ start_emo : num [1:30] 79.3 58.6 32.2 75.6 74.3 ...
..- attr(*, "label")= chr "Emotional symptom score at start"Longitudinal Data
- Another set of data issues you may face is in data collected over time, when one of two things happen:
- You want to analyze data by day or month or year, and data in your Electronic Medical Record is collected and time-stamped by the
second. - You realize that some observations (on weekends) are missing, and you need to fill these dates in as missing, but you really don’t want to do this by hand.
- You want to analyze data by day or month or year, and data in your Electronic Medical Record is collected and time-stamped by the
- The {padr} package can help with these issues.
Thickening Time for a Monthly Plot
- The thicken function adds a column to a data frame that is of a higher interval than the original variable.
- The variable
time_stamphas the interval of seconds - We want to thicken this (time stamped) data to month, then select and count overdoses
- This will set up the monthly overdose plot we want.
- We will thicken to month
- Then count overdoses by month
- This lets us count events like overdoses by month with time_stamp_month.
# A tibble: 11 × 2
time_stamp_month overdoses
<date> <int>
1 2015-12-01 91
2 2016-01-01 135
3 2016-02-01 141
4 2016-03-01 161
5 2016-04-01 124
6 2016-05-01 149
7 2016-06-01 140
8 2016-07-01 147
9 2016-08-01 137
10 2016-09-01 171
11 2016-10-01 95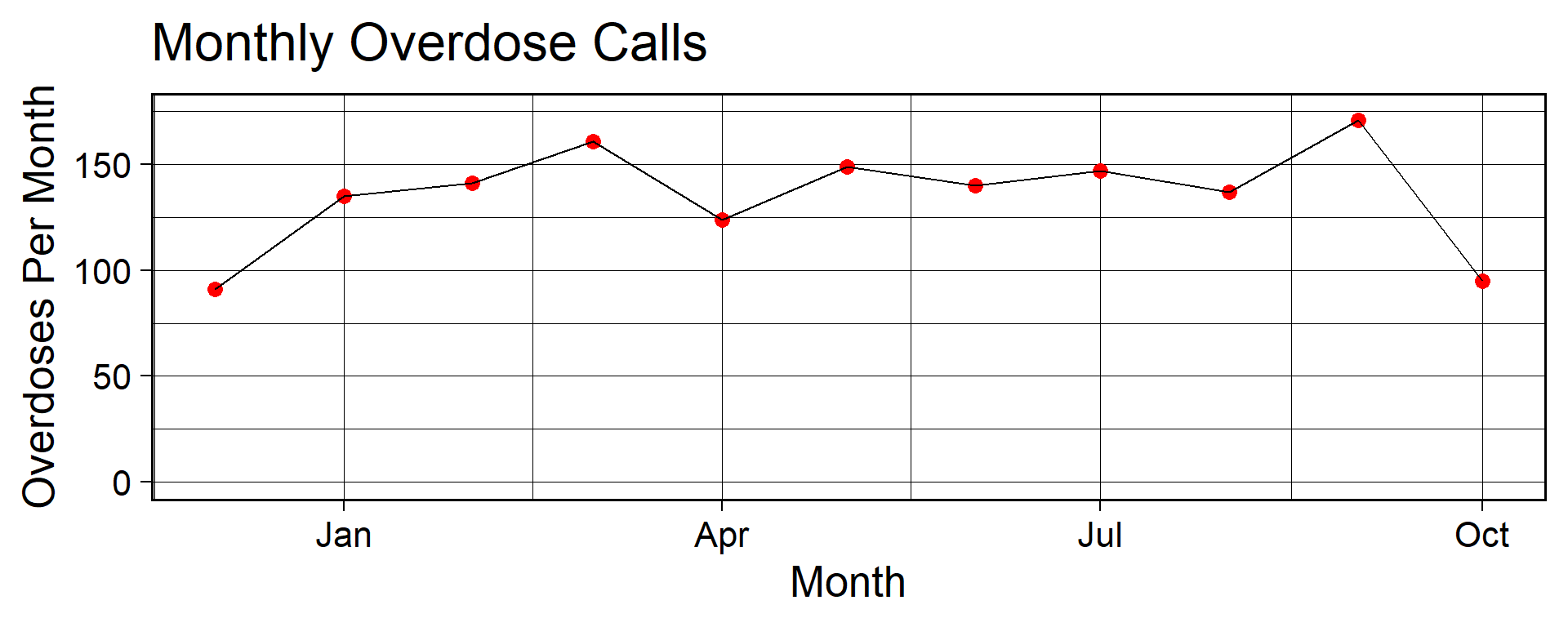
- When would you order extra cases of Narcan?
Joining Data
- Another data issue you will often face is that you have two interesting data sets, and that they would be more interesting if you could link the data in one to the data in the other.

Chocolate and Peanut Butter
(Datasets)
Joins of data from different sources
- We often collect data from different sources that we later want to join together for analysis
- Data from your local Electronic Medical Record
- Data from the CDC
- Data from the US Census
- External data can illuminate our understanding of our local patient data

Local Demographics with CDC SVI data
- We have 2 datasets, one local Demographics and Census Tract, and one from the CDC that has values for Social Vulnerability Index by Census Tract
- We want to know if the SVI for the neighborhood of each patient influences health outcomes
- We need to
left_jointhese datasets together by matching on the Census Tract
- What is the common uniqid/key?
- Local EMR data (
demo)
# A tibble: 9 × 4
pat_id name htn census_tract
<chr> <chr> <dbl> <dbl>
1 001 Arthur Blankenship 0 26161404400
2 002 Britney Jonas 0 26161405100
3 003 Sally Davis 1 26161402100
4 004 Al Jones 0 26161403200
5 005 Gary Hamill 1 26161405200
6 006 Ken Bartoletti 0 26161404500
7 007 Ike Gerhold 0 26161405600
8 008 Tatiana Grant 0 26161404300
9 009 Antione Delacroix 1 26161405500cdc
# A tibble: 9 × 2
census_tract svi
<dbl> <dbl>
1 26161404400 0.12
2 26161405100 0.67
3 26161402100 0.43
4 26161403200 0.07
5 26161405200 0.71
6 26161404500 0.23
7 26161405600 0.27
8 26161404300 0.21
9 26161405500 0.62- Replace the generic arguments to the left_join function to join the demographic data (demo) on the left to add Social Vulnerability index (svi) from the cdc dataset on the RHS. Left join by census tract.
- Now that the join is complete, you can ask your question:
- Is there an association between social vulnerability and hypertension?
# A tibble: 9 × 5
pat_id name htn census_tract svi
<chr> <chr> <dbl> <dbl> <dbl>
1 001 Arthur Blankenship 0 26161404400 0.12
2 002 Britney Jonas 0 26161405100 0.67
3 003 Sally Davis 1 26161402100 0.43
4 004 Al Jones 0 26161403200 0.07
5 005 Gary Hamill 1 26161405200 0.71
6 006 Ken Bartoletti 0 26161404500 0.23
7 007 Ike Gerhold 0 26161405600 0.27
8 008 Tatiana Grant 0 26161404300 0.21
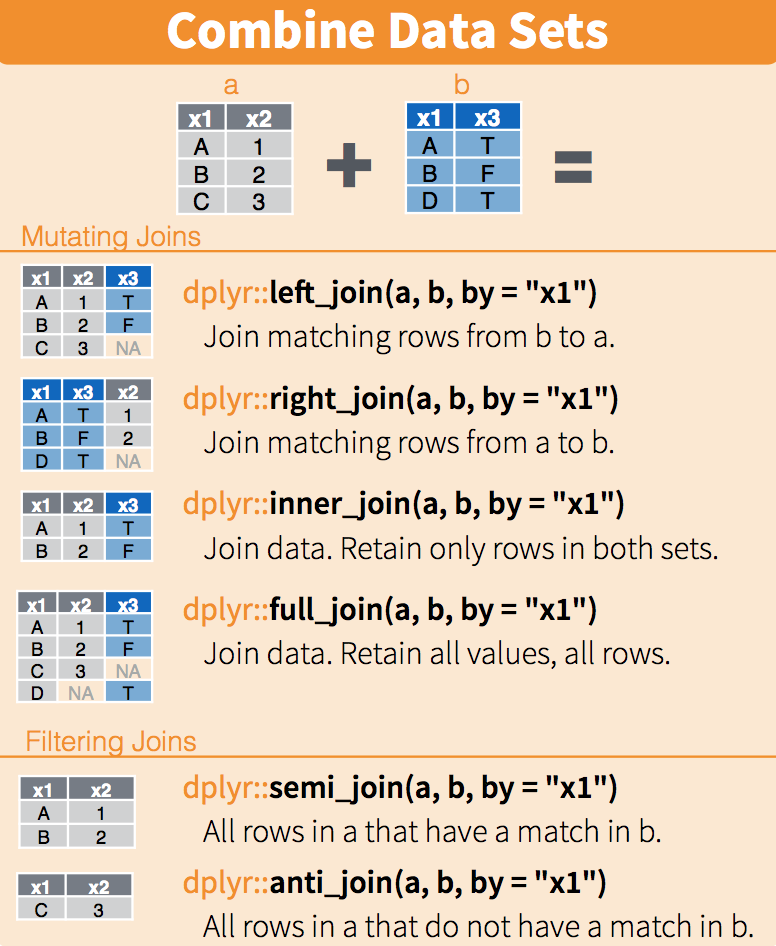
9 009 Antione Delacroix 1 26161405500 0.62What the Left Join Looks Like
This is a mutating join - new variables from y are created/added to the LHS (x).
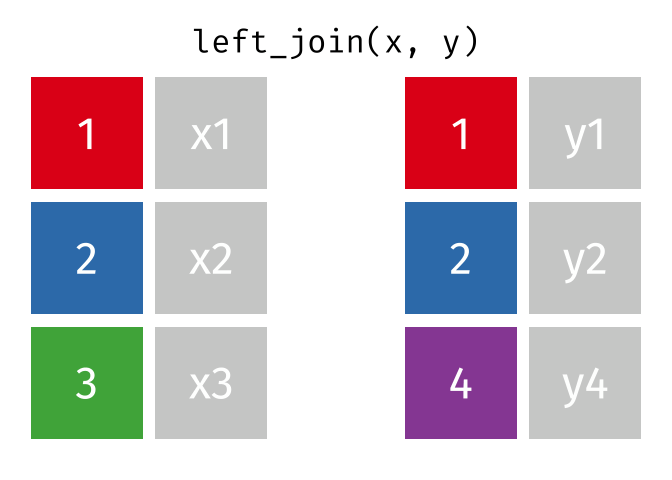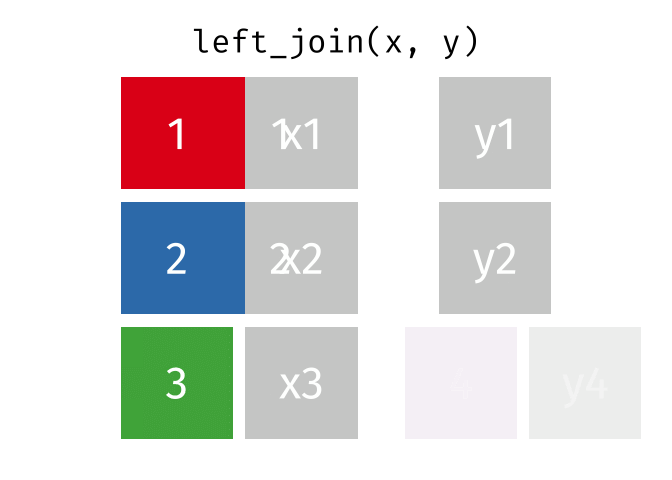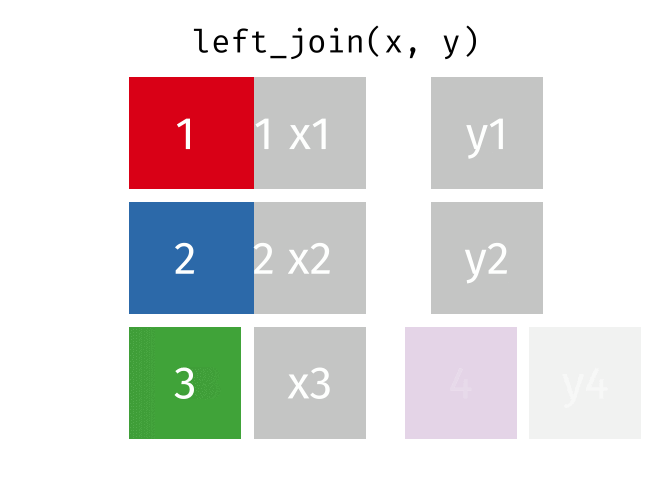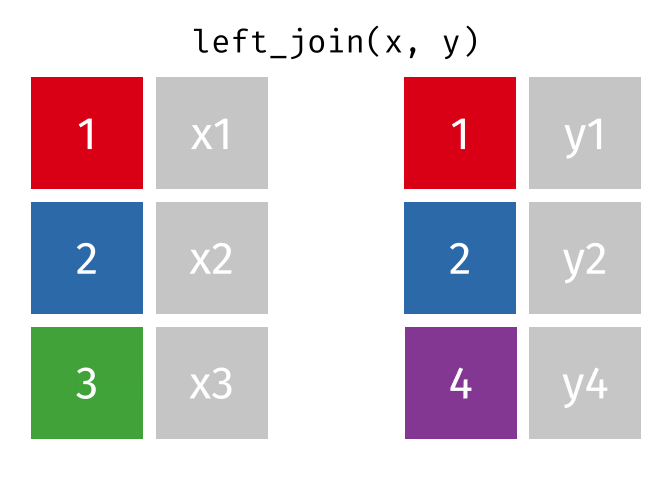
Workhorse Joins
- left_join is your workhorse. Start with patient identifiers/uniqid and add data to the right side.
- Sometimes you will need to wrangle/process incoming data, then pipe it in to right_join it to the patient demographics

Fancy Joins
- There are multiple kinds of fancy joins (semi_join, anti_join, inner_join, full_join, union, intersect, setdiff) which come in handy once in a while.
- The many kinds of joins are all well explained here
- Subset your data (x), keeping only the ones (y=hospitalized) who were hospitalized.

- Subset your data (x), keeping only the ones (y = dead) who are NOT dead.

Data Horror
Data So Messy, it Constitutes a Data Crime
What Should You Do?
Thank you!
Thank you for joining the workshop!
All materials will live on here: https://shannonpileggi.github.io/rmedicine-data-cleaning-2023/